This dialog is used to setup application settings:
Application settings are organized into tabs and groups with comprehensive descriptions. Below is the content of the dialog with some comments.
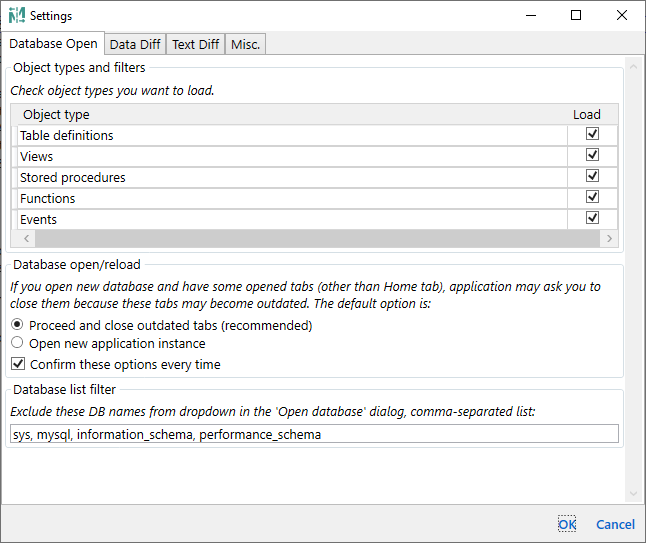
Check object types you want to load.
Object type list columns: Object type, Load
This list specifies which object definitions will be loaded and compared. When you open a database, the application reads all chosen object definitions from the database and keeps them in memory. For a large database it takes some time. Or, maybe you're not interested in some changes at all. Using these settings you can specify which objects you need to load. So, by disabling some object types, you can speed up database open process and keep your focus only on objects you need. Please note that if you omit some object type, then this can prevent some further merge actions. For example, stored procedure (SP) can depend on some view. If you need to merge this SP to the other side, then you will have to merge that view first. But if you'll disable views loading, then you will not able to do this and on merge you'll get an error from the database server that referenced view does not exist in the target database.
If you open new database and have some opened tabs (other than Home tab), application may ask you to close them because these tabs may become outdated. The default option is:
○ Proceed and close outdated tabs (recommended)
○ Open new application instance
☐ Confirm these options every time
It is the defaults for the Database reload dialog.
Exclude these DB names from dropdown in the 'Open database' dialog, comma-separated list:
(system database list)
This option removes specified databases from Database dropdown in the Open databases dialog. The default value is sys, mysql, information_schema, performance_schema.
These settings configure the default behaviour of the Data diff tab. String compare options are also related to the Batch data diff and Query result diff tabs.
Getting data by pages allows to work with large amount of data.
However it may be applied only if both tables have compatible prymary key.
You can specify page size as 0 to disable paging.
Default page size: (value)
You may select all records on the current data page, but if page size is less than total record count - probably you may want to process the rest of records on other pages. If this setting is enabled, then Data Merge/Delete will process all pages. Otherwise only current page is processed.
☐ Process all pages ☐ Confirm this every time
If the generated script will contain UPDATE statements, it can include all or only changed column values. In the last case, script will not be generated for unchanged rows.
☐ Update only changed columns ☐ Confirm this every time
Similarly to the data merge, if page size is less than total record count - application may ask you to whether you want to export all data pages or only the current one. Note that if any row is selected on any side, then only selected rows from the current page are exported (even if you select all rows on the current page).
☐ Export all pages
☐ Confirm this every time
These options affects batch data diff and the default state of text compare toolbar buttons for data diff. Batch data diff results needs to be re-calculated and any opened data diff tab needs to be refreshed to use updated options.
☐ Case insensitive
☐ Ignore leading and trailing whitespaces
Along with ignoring other whitespace changes, the last option also makes equal NULL and empty string
String compare options defines the default state of the  Case insensitive and
Case insensitive and  Ignore leading and trailing whitespaces vertical toolbar action states for the Data diff and Query result diff tabs. They also affect calculation logic for the Batch data diff tab.
Ignore leading and trailing whitespaces vertical toolbar action states for the Data diff and Query result diff tabs. They also affect calculation logic for the Batch data diff tab.
For all settings on this tab - projects needs to be reopened to apply updated options.
These options affects not only the default state of text compare toolbar buttons, but they also affects calculation of the changed objects on the Home tab and object list tabs.
☐ Case insensitive
☐ Ignore leading and trailing whitespaces
☐ Ignore ALL whitespaces (within a line)
☐ Ignore empty lines
Below you can specify additional custom text normalization rules to ignore more changes. See help for explanation on how it works. Please note that these options may have a huge schema diff performance impact.
Custom text normalization rules list columns: Enabled, Title, Pattern, Replacement. It is something similar to Ignore case or Ignore whitespace options, but they allow to set up more sophisticated rules. For example, but default this list contains only one disabled rule:
The following things needs to be taken into account when you use these rules:
Specify external diff tool for the 'Edit both in external diff tool' command.
Use %1 and %2 as placeholders for the left and right files (without quotes, they are added automatically).
If not specified, positional arguments (%1 %2) will be used.
(diff tool path)
Specify the full path to external diff tool exe file. If path contains spaces then it should be wrapped with quotes, but if you specify %1/%2 arguments, they should be out of quotes. Text diff Edit both in external diff tool command is shown only if this parameter is specified.
☐ Don't resize toolbar on application zoom
Max tab header width: (value)
Don't resize toolbar on application zoom allows to keep toolbar unchanged when you zoom application UI using  and
and  zoom toolbar actions.
zoom toolbar actions.
There can be the cases when object names are case-insensitive but have case differences in their names, for example on the left it is [MyTable] and on the right it is [myTABLE]. Application needs to handle it as the same object and there are places where it needs to show only one object name (for example in the Object List excel export or in the Batch Data Diff). Specify from which comparison side this name should be taken:
○ Left
○ Right
Default report file format: ○ *.xlsx ○ *.json
Any report needs to be saved to the file:
○ Ask new report file name every time
○ Auto-generate report file names and save to specified folder:
(reports folder path)
☐ Open generated report
This folder is used to store temporary copy of object definitions, binary and string data and generated data merge scripts.
Note that it's better to change this option without any projects/databases loaded, otherwise some old cache files may be not cleaned up in the old folder.
(local cache folder path)