This documentation page describes the behavior and content of the Id-Remap Merge dialog, which is opened to initiate the Id-Remap Merge process. For more information, explanations, and use cases regarding the Id-Remap Merge process, please see the Id-Remap Merge page in the Misc. section.
This dialog is opened from the Data diff and Batch data diff tabs after the following steps:
The application then displays this dialog to configure the Id-Remap Merge process. Once the configuration is complete, click OK and the application will generate data merge scripts, which will be shown in the Execute Script dialog.
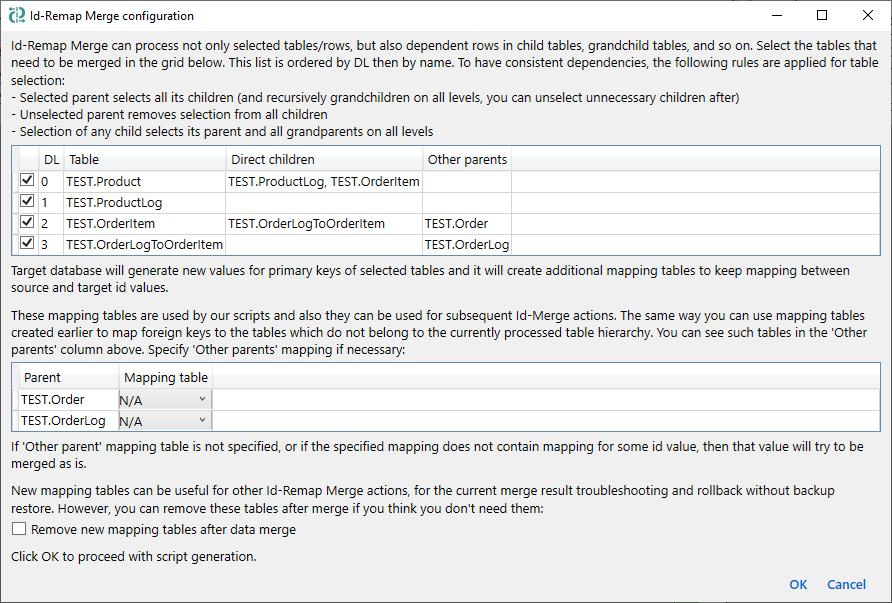
The dialog header explains the purpose and configuration rules of the tables list:
Id-Remap Merge can process not only selected tables/rows, but also dependent rows in child tables, grandchild tables, and so on. Select the tables that need to be merged in the grid below. This list is ordered by DL then by name. To have consistent dependencies, the following rules are applied for table selection:
- Selected parent selects all its children (and recursively grandchildren on all levels, you can unselect unnecessary children after)
- Unselected parent removes selection from all children
- Selection of any child selects its parent and all grandparents on all levels
Tables list columns:
The tables list is followed by explanations of the mapping tables:
Target database will generate new values for primary keys of selected tables and it will create additional mapping tables to keep mapping between source and target id values.
If the tables list includes any 'other parents', the dialog contains additional configuration for them:
These mapping tables are used by our scripts and also they can be used for subsequent Id-Remap Merge actions. The same way you can use mapping tables created earlier to map foreign keys to the tables which do not belong to the currently processed table hierarchy. You can see such tables in the 'Other parents' column above. Specify 'Other parents' mapping if necessary:
Other parents grid columns:
The 'Other parents' grid is followed by an additional note:
If 'Other parent' mapping table is not specified, or if the specified mapping does not contain mapping for some id value, then that value will try to be merged as is.
The dialog also includes an option, Remove new mapping tables after data merge, with the following description:
New mapping tables can be useful for other Id-Remap Merge actions, for the current merge result troubleshooting and rollback without backup restore. However, you can remove these tables after merge if you think you don't need them.
If you do not remove the mapping tables, they can be used in the 'Mapping table' dropdown in the 'Other parents' grid for subsequent Id-Remap Merge actions. See the Multi-Step Scenario #2 in the Id-Remap Merge article for more details.
By default, all tables to be merged are selected, and at the bottom of the dialog there is a notice indicating what will happen next:
Click OK to proceed with script generation.
If no tables are selected for merging, this text changes to:
Select at least one table to merge and click OK to proceed with script generation.