This tab allows to setup diff profile settings:
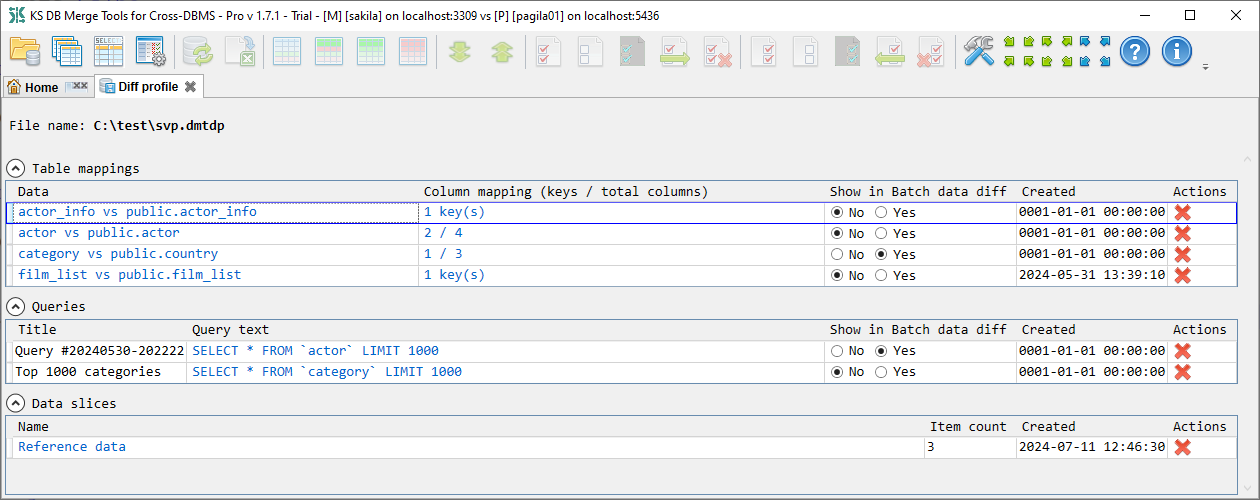
Tab shows diff profile file name in the header and has three collapsible sections: Table mappings, Queries and Data slices.
Table mappings section shows a list of saved custom data diff mappings. This list has the following columns and actions:
 Delete - remove these mappings from the diff profile.
Delete - remove these mappings from the diff profile.Queries section shows a list of queries saved using Query result diff tab. This list has the following columns and actions:
Delete - remove this query from the diff profile.Data slices section shows a list of saved data slices. New data slices can be created in the Batch data diff tab. This list has the following columns and actions:
Delete - remove this data slice from the diff profile.Custom schema/name mapping rules allow to set up custom rules to match schemas and normalize object names across different naming conventions. For example, to remove delimiter chars from name, setup schema mapping, and provide automatic table match like prod.sale_preson vs Product.SalesPerson.
☐ Use custom rules [Save changes] [Discard changes]
Db1 / Schema1 / Name1 refer to the database opened in the left panel.
Db2 / Schema2 / Name2 refer to the database opened in the right panel.
Schemas processing allows to setup schema mapping and extract part of object name in schema-less DBMS that can be mapped to a schema in schema-based DBMS. For example, for MySQL table prod_salesperson we can extract "prod_" as a scheme and then using prod_ vs Production mapping map automatically prod_salesperson to Product.SalesPerson in SQL Server.
☐ Match objects by schema and name (overwrites related Schema Diff setting)
Extract schema from table name prefix in schema-less DB to match schema-based DB (comma-separated list):
(prefix list)
Schema mappings:
(schema mappings table, columns: Schema1, Schema2)
Names processing allows to setup name normalization rules to automatically match objects between databases using different object naming conventions:
Normalize object names to match across different naming conventions (e.g., tblUserLocations vs user_location).Each rules table has columns Trim At (dropdown of Start, End and Everywhere), Value, and Max Count (for Everywhere). Max Count is ignored for Start and End, and it is optional for Everywhere. Rules are applied in the same order as they are listed. For example, for the object name "prod_sales_person":
For special cases not covered by normalization, use Explicit object mappings (see below).
☐ Use same normalization for both databases
☐ Normalization for Db1: (rules table) ☐ Normalization for Db2: (rules table)
Explicit object mappings are the top-priority rules to handle special cases that can't be covered by general rules:
These mappings override the schema and name handling rules specified above. Use it for special cases which can't be covered by general rules.
Specify both schema and name for schema-based DB and name only for schema-less DB.
(schema mappings table, columns: Schema1, Name1, Schema2, Name2)